

End of the year was approaching quickly, and the DevOps team was looking for a volunteer that could stay on standby should the infrastructure require attention. Since Tintri engineering is distributed across 3 continents, some of the teams rely on operational dev systems throughout the holiday season. See, keeping 70 racks worth of gear up, running, and healthy in our Santa Clara data center does not necessarily go well with the end-of-the-year shutdown we “observe” in North America.
Hearing about this ask I thought that this could be a great opportunity to “drink our own champagne”, since most of the infrastructure is built on Tintri systems. I’ve always been adventurous, and besides, what’s the worst that can happen?
Fast forward 1.5 months to the end of December and there I was, working from my home office, browsing through the various infrastructure components to make sure that everything is working well.
Connectivity looks good – Check
No scary logs on the core switches – Check
vCenters – Check
And then I saw it – One of the datastores was at 97% capacity used! Reaching 100% obviously means service interruption!
How could this happen? How come no one saw it???
Tintri makes realIntelligent Infrastructure. This simply means that Tintri infrastructure can take care of itself while making sure that all VMs and applications are healthy and benefit from great service at sub-millisecond latency.
Filling up a datastore should never happen. When set up correctly, Tintri Global Center monitors the current load and predicts future consumption. It then knows how to optimize the workloads footprint on the various Tintri VMstore systems to make sure that none of them reaches a 100% utilization on performance and capacity.
The only thing that the admin has to do, is group together a collection of VMstore systems into a “Pool”, kind of creating a cluster. This indicates to Tintri Global Center which VMstores can share virtual machine load and TGC then does the rest.
But Pools, I learned, weren’t set up on our DevOps system – speaking of drinking our own champagne…
Looking at the bright side, this was an excellent opportunity to make sure that Tintri VMstore and Global Center actually work as advertised and become a hero for preventing an outage. Therefore, as I was trying to find out how to clear some space, I’d setup a new Pool in Tintri Global Center and let it do its thing.
Here is a summary of the analysis that was done automatically by the system, as displayed in the screenshot below:
- Current issues:
- One VMstore is about to run out of space – well, we knew that already…
- Recommended action:
- Migrate 4 VMs – with specific details on the exact VMs in the recommendation
- Outcomes:
- More free space on one system, more space consumed on another system – exactly what I wanted!
All I had to do is hit the “Execute” button and go back to my holiday vacation!
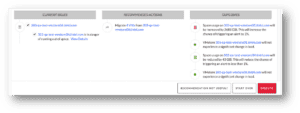
Note – it is extremely important to choose the right VMs to migrate. Since most modern storage arrays apply deduplication and compression to the stored data, we want to choose VMs that actually have lower space savings, since migrating these will result in more physical free space.
Tintri VMstore knows the space savings factor for each VM and therefore Tintri Global Center already provides the most efficient recommendations. This is where other solutions such as VMware Storage DRS struggle. They might trigger migration for a VM that most of its data is deduplicated against other data on the storage array, leading to a long and heavy Storage vMotion operation that result with minimal freed-up space, or more likely using more space in aggregate.
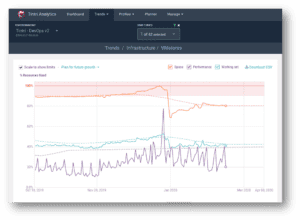
Now even without Pools, we could have seen this coming: Tintri Analytics clearly shows the current resource consumption as well as examine future trends and predictions.
As you can see in the following screenshot, it is super-easy to know when you’re about to run out of space, even months before it actually happens. Here is the Tintri Analytics graph for the VMstore that was about to run out of space. Check the orange line that indicates space utilization – almost hitting 100% in December!
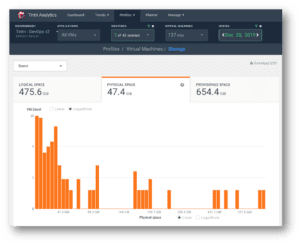
Clicking on this graph takes us directly to the VM breakdown at the specific point in time. Here we can see exactly which VMs consume most space at the given date. The average VM size is 47.4 GiB, with a few VMs on the right end of the graph that consume around 400 GiB. Clicking each line reveals the VM names, but I spared you that part.
All this information and we didn’t even have a chance to discuss how advanced the actual VM migration process is on VMstore. In summary, Intelligent Infrastructure is all about having the systems work for you, and we can leave the details for the next post.
Yours truly,
Tomer


